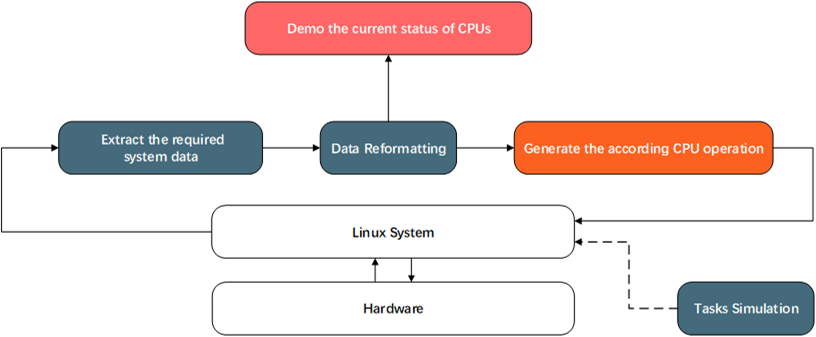
Problem Statement
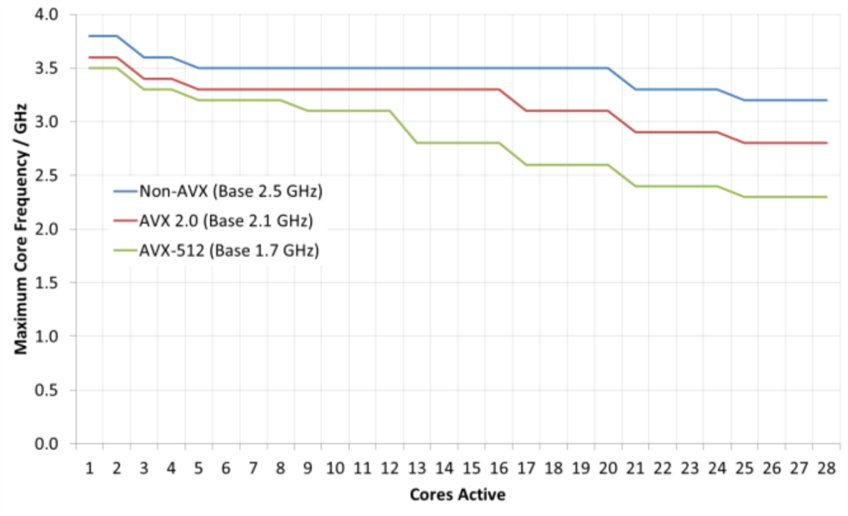
Nowadays, technology is booming. The scientific and engineering research, and also many high-tech applications, require high efficiency of floating-point calculation. Therefore, AVX512 instruction set is given to birth. However, in practical experiment, a problem has been found: The throughput of Non-AVX tasks will suffer unexpected decrease when there are AVX512 tasks running on the same server. This project is to avoid the throughput decrease of Non-AVX tasks, in order to achieve the optimal overall efficiency of the server.